
nanograph: on-device graphDB for agents [and humans]
The case for local-first, schema-enforced graphs in agentic workflows

I built my own graph database.
Here is why:
I love graphs and I use them A LOT!
for agent memory
for structuring project context
for building compounding knowledge bases
Yet old-school graph databases are too heavy for agentic workflows.
They are cloud-first monoliths built for enterprise infrastructure:
Servers, Docker, slow MCPs, and schema maintenance hell.
nanograph started as a question:
What if graphs felt like SQLite/DuckDB - open, query, done - but with types, migrations, and ergonomics built for agents?
Quick to tear down and rebuild, safe enough to trust, and simple enough to keep in the repo.
I could not find a graph database aligned with this vision.
So I built it.
An on-device, embedded, schema-as-code graphDB.
Now let's unpack this:
Why graph?
Why on-device?
Why schema-as-code?
Why graphs?
Graphs help agents reason through data.
Agents are informed walkers.
When an agent investigates an issue, it traverses a context graph.
Graphs give the agent reasoning structures.
Now add decision traces to the equation: the explicit HOWs and WHY - workflows, exceptions, reasoning.
Agent now can:
Solve a problem → walk the graph → write a new trace → graph compoundsNew reasoning paths are created - agent becomes even smarter.
BTW the graph doesn't need to be standalone.
It can sit as a semantic layer on top of your data:
SQL/NoSQL or a collection of MD files.
Why on-device?
Coding agents pull us back to fundamentals:
Filesystem, CLIs, Markdown, SQLite/DuckDB.
In PKM, Obsidian is winning, and tools like qmd are getting real traction.
If everything is on-device, everything is simple.
Totally private by architecture, not by policy.
And you can use your own tooling even inside heavily regulated enterprise environments.
Agents want direct, fast, deterministic access to data.
They don't want MCP auth or deal with connection errors.
Why schema-as-code?
Non-enforced schema means garbage accumulation.
Agents are incredibly creative!
Give them a schemaless graph and they will roam free.
They'll invent edges like knows, met, connected_to, spoke_with - all meaning the same thing.
That creates precedent poisoning.
Semantic drift propagates through the reasoning layer.
Your graph becomes noisy, retrieval becomes unreliable.
An established schema prevents it.
And schema-as-code is the best way to enforce it and track changes.
Additional benefit: it captures the evolution of your contract with the agent.
That contract changes as your modeling changes.
Track schema history and the agent can see how your model evolved.
It becomes another super-useful reasoning trail.
So what is nanograph?
nanograph is an on-device graph database packaged as a CLI + a folder.
Engineered around five pillars:
On-device - the graph is a folder, not a service. No Docker, no cloud, no open ports. Super-fast local queries vs slow cloud roundtrips - compounded across hundreds of agent calls per session.
Zero setup - nanograph init creates a database from a schema, nanograph load ingests data. Delete the folder and recreate in seconds. No migrations server, no connection strings.
Schema-as-code -
.pgschema files live in your repo, version-controlled right in your repo. Types are enforced at load time and query compile time.Time machine - built-in CDC and event sourcing. Every mutation is a ledger entry. Full audit trail without external dependencies.
Power search - full-text, semantic, fuzzy, BM25, and hybrid search with graph-constrained reranking. Traverse edges to narrow the candidate set, then rank within it. Search inside context, not across the whole database.
A nanograph database is a build artifact, not a running service.
It is a folder: <name>.nano/ that contains all your graph data: copy it, git it, zip it, encrypt it.
Building DB on this paradigm way was quite challenging.
Claude Code and Codex are incredible at writing Rust code.
But when working on specs, architecture and ergonomics - LLMs gravitate towards default thinking and generic components.
Because I wanted to build nanograph as a frontier graphDB,
I dug beneath the surface: researching state-of-the-art open source components.
I was able to figure out a clever interplay between Apache Arrow for memory model and Lance format for storage.
Then I spent a lot of time designing the query language: nanoQL
trying to merge Datalog semantics with GraphQL-shaped syntax.
By this point I had a working prototype, which felt just right!
After having a proof of concept, I dug one layer down and started to work on nuances.
I thought I knew a lot about databases - I've worked with them all my life.
But here I realized that everything is waaay more nuanced and complicated than I imagined it to be.
I went deep into first principles: indexes, compaction, WAL, CDC, caching, ordering, lexical retrieval, hybrid search.
This book was incredibly helpful in figuring out first principles.
After getting the fundamentals right, I started working on specs for each feature super-smart models (GPT-5.2 PRO and Gemini 3 Deep Thinking).
Operating on the edge of my own engineering and math competences,
I was able to optimize all key processes and make nanograph really fast and stable.
nanograph is the most elegant piece of engineering I've ever done.
I really encourage you to try it out!
Quick start
You can just give your agent a link to the repo and it will do the full setup for you:
https://github.com/aaltshuler/nanograph
Or set it up manually:
brew install protobuf
cargo install nanograph-cliThe repo ships two ready-to-run example graphs.
Star Wars graph

A knowledge graph of characters, films, factions, and mentor relationships - 9 node types, 25 edge types, 66 nodes. Great for exploring schema basics, graph traversals, and the full search stack (text, semantic, hybrid).
The schema defines typed nodes with enums and @key identity:
node Character {
slug: String @key
name: String
species: String
alignment: enum(hero, villain, neutral)
}
edge HasMentor: Character - Character
edge DebutsIn: Character - FilmInit, load, and query:
nanograph init sw.nano --schema examples/starwars/starwars.pg
nanograph load sw.nano --data examples/starwars/starwars.jsonl --mode overwrite
nanograph run --db sw.nano --query examples/starwars/starwars.gq --name jedi
nanograph run --db sw.nano --query examples/starwars/starwars.gq --name students_of --param name="Yoda"Queries are typechecked against the schema - wrong property names, type mismatches, and invalid traversals are caught before execution.
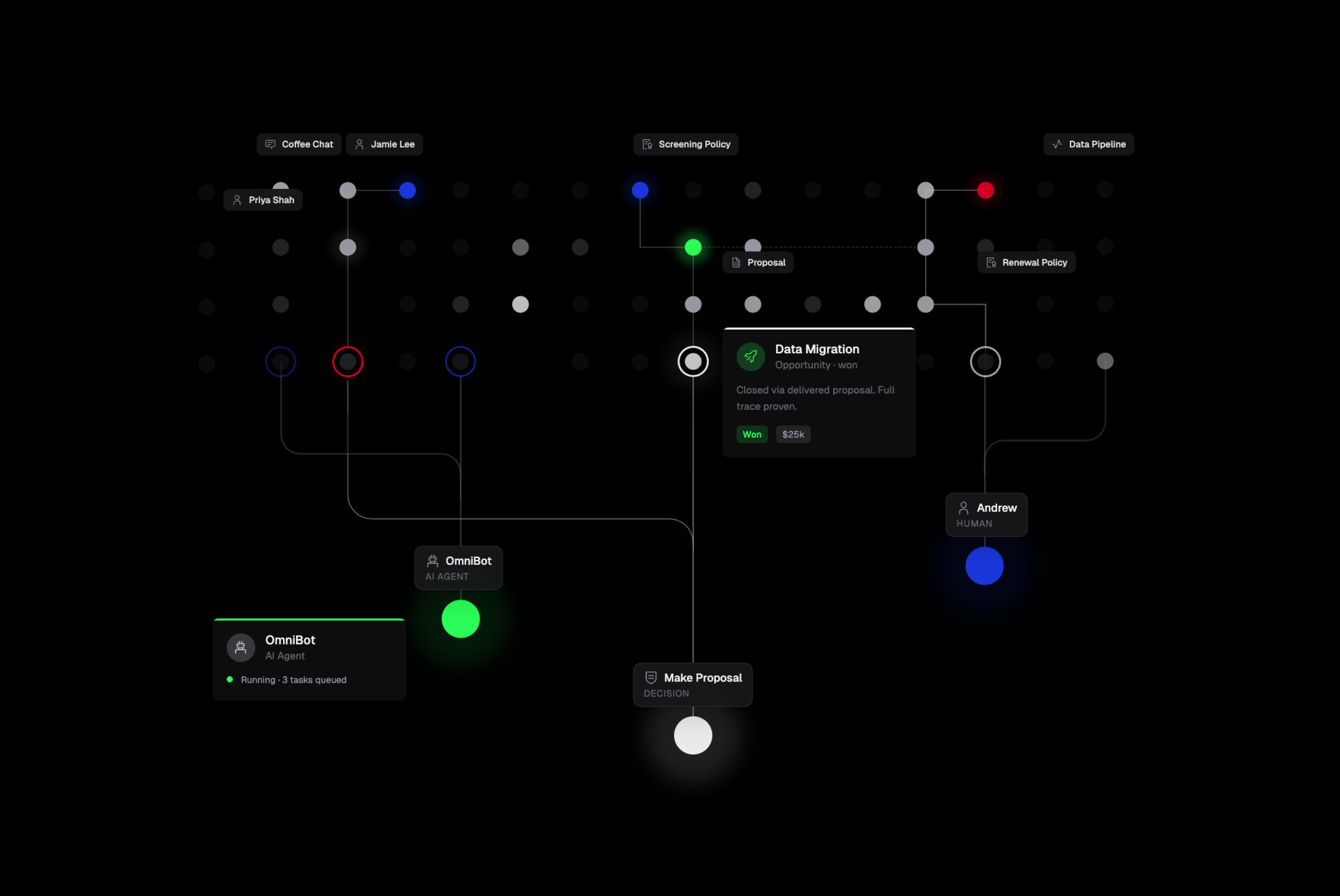
RevOps context graph
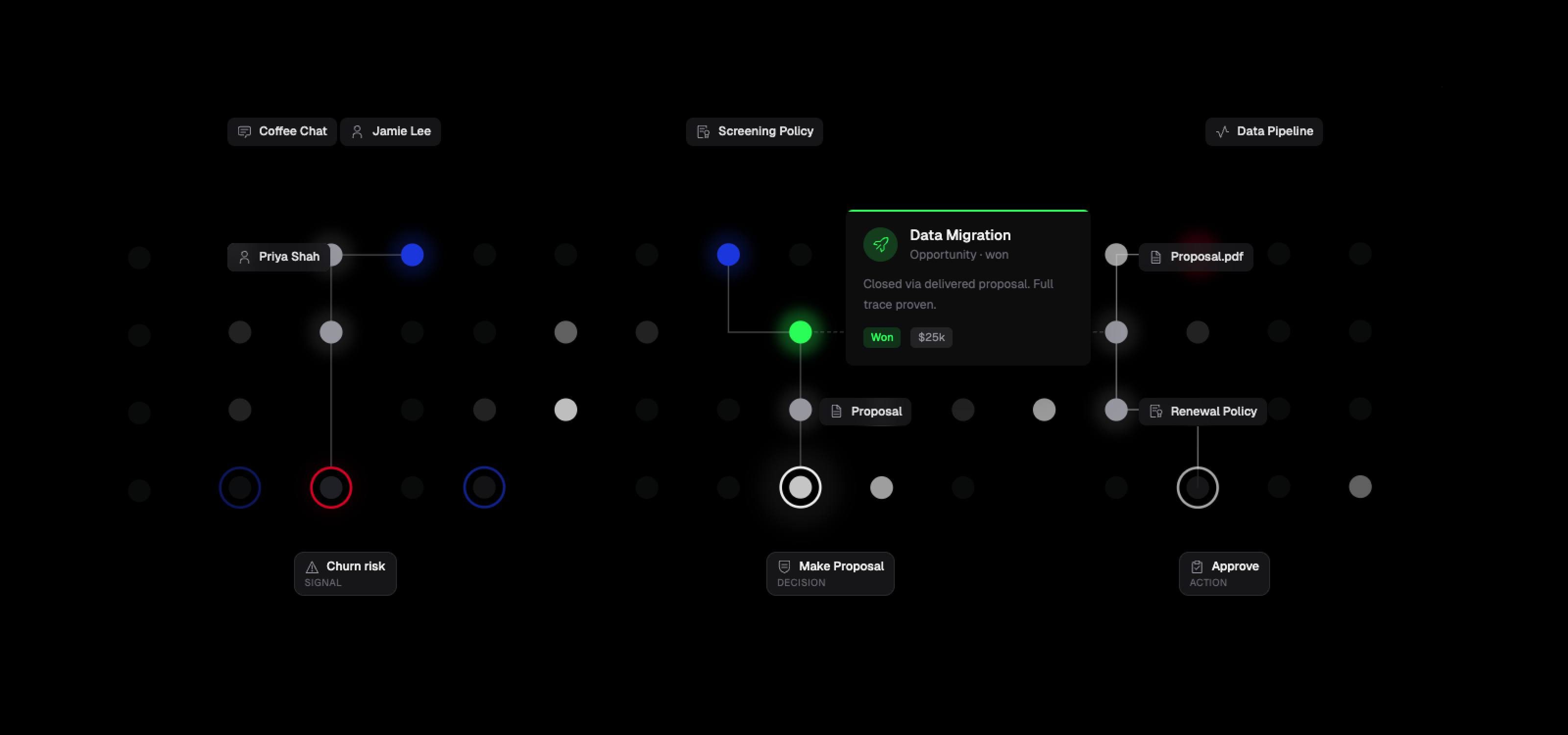
A RevOps context graph:
intelligence capture → enrichment → screening → decision → delivery.
10 node types
21 edge types
This is where nanograph's design really shines: decision traces, policy versioning via Supersedes edges, and multi-hop traversals from signals to outcomes.
nanograph init omni.nano --schema examples/revops/revops.pg
nanograph load omni.nano --data examples/revops/revops.jsonl --mode overwrite
# trace why a decision was made
nanograph run --db omni.nano --query examples/revops/revops.gq \
--name decision_trace --param opp=opp-stripe-migration
# close the loop: signal → decision → action → outcome
nanograph run --db omni.nano --query examples/revops/revops.gq \
--name full_trace --param sig=sig-hates-vendorThe decision trace query walks from an opportunity back through who decided and what signal drove it - the kind of "why did this happen?" question that agents need to answer.
What nanograph is best for
Context graphs (decision traces, causal chains, structured context)
Agentic memory (typed on-device memory for coding agents)
Personal knowledge (bookmarks, notes, connections; local-first, schema-enforced, versioned)
Dependency graphs (services, packages, lineage tracking)
What nanograph is not for
nanograph is intentionally not trying to be everything.
not a multi-tenant distributed cloud graph
not an everything-store without schema discipline
not a transactional system-of-record or ledger
The point is the opposite:
Keep your nanographs compact, isolated, typed, and focused.
Have as many of them as you need.
Init is seconds, delete is seconds.
Spin up per-project, per-agent, per-experiment.
nanograph is open source and free to use.
Your agent will download it and set it up for you,
then help you create your schema and ingest your data.
If you like it - please give it a star on GitHub⭐